
テクログ(テクニカル・ブログ)では、弊社エンジニアのIT技術おけるさまざまな情報やノウハウなどをお届けします。
こんにちは、A10ネットワークスで、システム・エンジニアを担当している甲野 謙一です。
今回は、ロードバランサーの主な役割である冗長化と負荷分散に注目して、A10ロードバランサーのスケールアウト構成とトラフィック・フローを解説します。
スケールアウト技術登場の背景
冗長化といいますと、古くは1980年代頃からハードウェアの主要回路を冗長化し、故障があってもノードそのものを停止させずに無停止で稼働させ続けるシステムとして、タンデムコンピューターズ社やストラタステクノロジー社による無停止コンピュータ(フォールトトレラントコンピュータ)が商用稼働したことにさかのぼります。インターネットの発展とともに、単一ノードを停止させてもネットワーク・システム全体を停止させずにサービス提供を安価に提供させる仕組みが模索されました。1996年ごろから、ロードバランシングの1形態として、サーバー・ロードバランサーが世の中に登場して24年経ち、今日では、ロードバランサーは冗長化と負荷分散の手法として、またネットワークをスケールさせる重要コンポーネントとして、確固たる地位を築きました。
ロードバランサー(以下、LB)の提供する冗長化とは、1台のサーバが故障しても他のサーバによってサービスを継続するものです。また、負荷分散とは1台のサーバでは処理しきれない負荷をLBが複数サーバの振り分け、スケールアウトさせることにより全体性能を上昇させるものです。
典型的な構成は、次のとおりとなります。
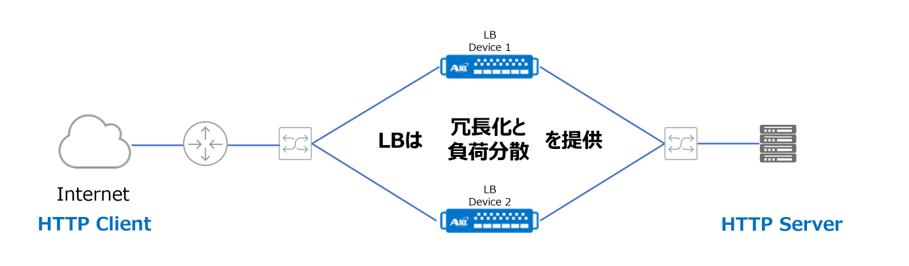
1台のLBが故障した場合もサービスを継続するため、LBを2台以上で構成することが基本です。 とろこが、正常時は1台のLBが冗長化と負荷分散を提供するため、1台のロードバランサーに負荷が集中すると、LB自体がボトルネックになる課題があります。従来、LBのボトルネック解消するためには、より上位機種にアップグレードをするしかありませんでした。そのうえ、トラフィックの伸びや、あるサービスがどれだけヒットするかを事前に予測して最適なLBを配置することは難しかったため、ゲーム業界やWeb業界を中心にスケールアップよりはスケールアウトする手法が求められていました。
A10ネットワークスでは、2014年12月にリリースしたACOSバージョン4.0より、スケールアウトをサポートしております。それ以降、モバイル・キャリアにおけるCGNAT分野でのスケールアウトの導入実績を重ねており、現在はLB分野でも徐々に導入が始まってきた状況です。 本ブログでは、ACOSバージョン5.1.0-P3での典型的なA10 LBのスケールアウトの構成とトラフィック・フローに関して解説します。
A10スケールアウトのネットワーク構成
まず、以下の図に示す構成で、A10スケールアウト用語の解説です。
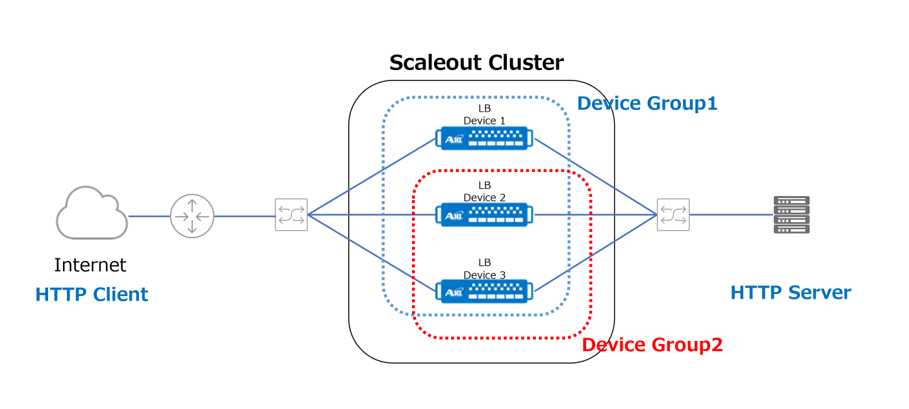
最小1台、最大8台で構成可能ですが、ここでは3台のLB DeviceでScaleout Clusterを構成しています。
●1つのVIPによりサービスを分散するグループをDevice Groupと呼びます。
Deviceの台数内で自由に定義できますが、例として「Device Group1は、Device 1、2、3で処理を分散し、Device Group2はDevice 2と3で処理を分散する構成」で説明します。Device Groupに紐づいたVIPは、arpに応答するIPアドレスで構成するか、arpに応答しないloopback IPのようなIPアドレスで構成します。arpに応答しないIPの場合は上位L3スイッチにおいて、等コストのstatic routeをThunderのfloating-ipに向けるか、ThunderでOSPF/BGPのようなDynamic Routing Protocolを使用して等コストでVIPを広報します。 Scaleout Cluster内のLB Deviceは、Cluster MasterまたはService Nodeの役割が割り当てられます。
●Cluster MasterはTraffic Mapを作成する役割とScaleout ClusterへのService Nodeの追加と削除を維持・管理する役割があります。
●Traffic Mapとは、Device Groupによって処理されるVIP宛てのIncoming TrafficがどのThunderで処理するかを記載したリストです。
Device Group1を例にすると、全てのHTTP ClientのSource IPは、Device Group内のDevice 1、2、3のどのDeviceが通信を着信するのか、という対応表がTraffic Map にあります。
●「LB Device 1が、あるSource IP からのIncoming Trafficを受信したが、Traffic MapにはSLB ownerはLB Device 2であると記載されている」場合に、LB Device 1はLB Device 2へ通信をRedirectします。
●「Traffic MapにLB Device 3と書いてあるIncoming TrafficがLB Device 3に着信した」場合は、RedirectなしでbackendのHTTP serverに転送されます。
| A10スケールアウト用語 | 詳細 |
|---|---|
| Scaleout Cluster | Scaleoutを構成するThunder deviceのグループ |
| Cluster Service | Scaleout Custerによって提供されるVIPあるいはvPort |
| Traffic Map | Scaleout Clusterによって処理されるVIPあるいはvPort 宛てのIncoming Trafficが、どのThunderで処理するかをMappingしたリスト。実際にL4/L7 SLB処理するdeviceをSLB ownerと呼ぶ |
| Cluster Master | Traffic mapを作成するNode。また、Scaleout Clusterへの他のデバイスのJoinとLeaveを管理する役割を担う。Cluster Masterは設定するPriority値の最も大きいデバイスが選択される |
| Service Node | Incoming TrafficをSLB或いは他のThunderにRedirectするTrafficを識別・分散・処理するエンジンとして動作するNode。Cluster MasterもService Nodeの役割を兼ねる |
| Device Group | Cluster Serviceに対して、ADCサービスを提供するThunderのSub-Setグループ。Cluster Serviceごとに、SLBを処理するThunderのグループを変えることが可能 |
A10スケールアウトのトラフィックの流れ
VIPへの通信がどのように処理されるかを以下のステップで解説します。
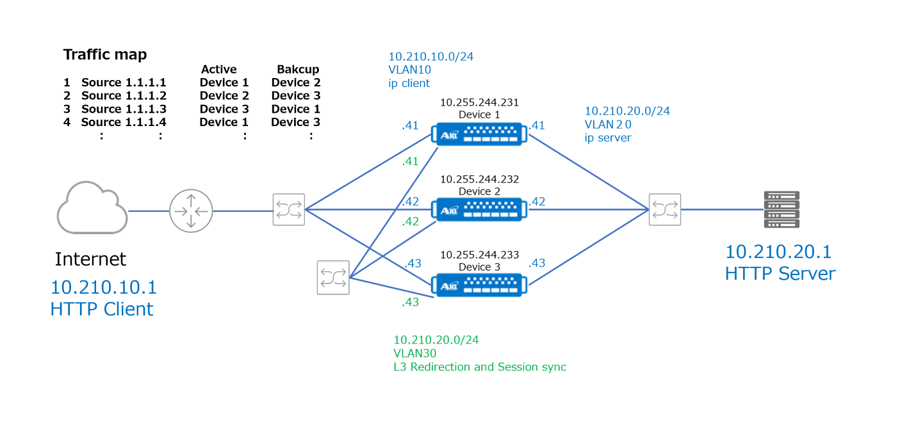
- Cluster MasterであるDevice 1がTraffic mapを生成し、Service Nodes(Device 2、3)に配布する。
- Upstream routerがVIP宛てのTrafficを受信、Upstream routerはVIPに対するARP解決をする。
●どのDeviceが、VIPに対するARPのResponseを返すかは、Virtual-Server名のHashで決定する。
- 例として、HTTP Clientからのリクエストを、まずDevice 3が受信する。
- Device 3は、Traffic mapに従い、Device 1やDevice 2にRedirectする。
●この際のRedirectは、VIPを着信したInterfaceで実施することもできる。
●転送効率の観点から、上記構成図のVLAN30のように、Redirect用ネットワークの使用を推奨する。 - Device 1、2はSource NATを行いながら、HTTP ServerへのServer Load Balancingを実施する。
●この際のSource NATは必須ではないが、Redirectにより転送効率が落ちる。
●HTTP ServerからのResponseもredirectすると、転送効率が落ちるので、Source NATを推奨する。 - Device 3がSLB ownerとなるSource IPからのリクエストであれば、redirectせずそのままSource NATを行いながら、Server Load Balancingを実行する。
まとめにかえて
今まではLBを2台で構成をすると、VIPが1つの場合は1台のLBがSLB処理を行い、もう一台は処理しない構成が「LBの典型的な構成例」でした。VIPを2つ設定すれば2台それぞれのLBがSLB処理することは可能です。ですが、サービスの稼働は1つのVIPで運用したいことが多く、2台構成のLBにそれぞれ1つずつのVIPを設定する構成はあまり使われてきませんでした。
ここで解説した構成はDevice 1、2、3がL2接続されている構成でしたが、実際にはL2接続されている必要はありません。特に、仮想環境へvThunderを適応する場合、Thunder Device同士がL2接続できないことがあります。
L3構成の場合にはUpstream RouterにおいてECMPで同一VIPをRoutingし、それぞれのDeviceがVIP宛のIncoming Trafficを受信できるように構成すると、最初に受信するトラフィックから分散できますので、Redirectが発生しない分だけ転送効率が上昇するため、Thunder間の負荷を最適化できます。
L2構成の場合も、ECMPで最初に受信するトラフィックから分散すると、Redirect低減による効率化が期待できます。
このA10のスケールアウト技術を適応すると、LBサービスのスモールスタートが可能で、必要に応じてスケールアウトさせることが出来ます。LB性能が特に必要なL7のHTTP、HTTPSの分散に関して、効果的に利用できると考えています。また、どのDeviceがVIPを処理するかは、Device Group毎に設定が可能ですから、DeviceのCPU/Memory/Throughput等の負荷状況を見ながら、Cluster ServiceをDevice間で動的に遷移させることにより、Deviceの稼働率を調整することが可能です。
ぜひ具体的な検証と導入をご検討ください。

システム・エンジニア
甲野 謙一
過去のテクログ
『Office 365などのSaaS利用を快適にするネットワークの高速化・可視化』 石塚 健太郎
また、A10ネットワークス WEBサイトのブログからもご覧いただけます。

